Microsoft’s Secure Future Initiative (SFI) is highly relevant at the board level because it turns “security-first” from an aspiration into enforceable engineering and operational standards. It is built on three core principles—secure by design, secure by default, and secure operations—supported by prioritized engineering actions. For data professionals, its value is most evident in how it translates into measurable controls: robust encryption and key management, tightly governed access (including vendor and support access), continuous compliance evidence, and standardized “paved paths” that minimize misconfigurations and reduce operational risk.
For Nigeria’s critical infrastructure operators, compliance is shifting toward risk-based regulation and sector-specific resilience requirements. Key frameworks driving this include the Nigeria Data Protection Act 2023, the NDPC GAID 2025 implementation directive, the CBN Risk-Based Cybersecurity Framework (2024) for banks and payment service providers, and the Critical National Information Infrastructure (CNII) Order 2024, which defines critical sectors and mandates protection planning, auditing, and trusted information sharing.
Continuity, Data trust, and Sustainability as One Governance Problem
A useful board lens is to treat data trust as an “availability and integrity” problem, not only a privacy problem. If the board cannot trust the lineage, access path, and control evidence for data and models, it cannot trust downstream decisions (credit, fraud, grid dispatch, telecom routing, citizen services) or the continuity plans built on those decisions. This aligns with modern risk frameworks that emphasize lifecycle governance and context-aware risk, rather than one-time certification.
Business continuity and digital trust also increasingly intersect with sustainability. AI-era continuity plans must anticipate energy and cooling constraints (especially for large-scale compute), while sustainability governance increasingly requires measurable emissions reporting and optimization. Microsoft publicly commits to being carbon negative, water positive, and zero waste by 2030, and provides customer-facing tooling such as the Emissions Impact Dashboard to estimate cloud-based emissions and avoided emissions from migration scenarios.
For boards, the practical implication is that “secure, compliant, and resilient” procurement should also ask: Can we measure and optimize the carbon footprint of the workloads we are scaling? That question becomes material when AI workloads expand rapidly and continuity depends on predictable, costed infrastructure scaling.
How Microsoft Builds Differently to Meet SFI Expectations
SFI is not merely a messaging layer; Microsoft positions it as a company-wide security initiative with measurable standards, “paved paths,” and prioritized engineering pillars. The Trust Center description emphasizes setting and measuring standards across six prioritized security pillars, and the Microsoft Learn overview explicitly connects SFI pillars to Zero Trust principles and to the NIST Cybersecurity Framework mapping. The April 2025 progress report executive summary describes large-scale engineering investment and reiterates the three principles: secure by design, secure by default, secure operations.
A board-level way to make SFI “actionable” is to translate it into procurement and architecture checklists that can be evidenced through specific cloud features and auditable artifacts (policies, logs, attestations, and independent reports). The table below maps SFI expectations to concrete capabilities and verification sources.
| SFI expectation (what “good” looks like) | What it means in practice (board/data lens) | Concrete Microsoft capabilities to look for | Primary references for verification |
|---|---|---|---|
| Protect identities and secrets | Reduce credential-based compromise; control key material and secret sprawl | Customer-managed keys (CMKs) and BYOK patterns; Managed HSM for key custody; documented key management model | Key management in Azure |
| Protect tenants and isolate systems | Limit blast radius; reduce cross-tenant lateral movement; isolate production | Policies and standards aligned with SFI tenant isolation goals; board should require explicit isolation boundaries in architecture and incident postmortems | Secure Future Initiative |
| Protect engineering systems (supply chain) | Treat model + code pipeline as a supply chain; require provenance and integrity controls | Align secure engineering with recognized secure SDLC practices (SSDF) and CI/CD supply chain security guidance | Secure Future Initiative (FSI) |
| Monitor and detect cyberthreats | Continuous detection with evidentiary logging; board reporting that is trendable | SFI pillar emphasis on monitoring/detection; evidence should include logs, alerting, and response KPIs | Secure Future Initiative |
| Secure operations | Ongoing security controls; structured response, post-incident learning, and hardening | Customer Lockbox as a control over provider support access to customer data; audit logs for approval/denial | Customer Lockbox for Microsoft Azure |
| Compliance evidence and external assurance | Ability to present independent audit artifacts to regulators and customers | Service Trust Portal (SOC/ISO reports, compliance materials) and compliance documentation portfolio | Service Trust Portal |
| Confidentiality for sensitive workloads | Protect data not only at rest/in transit, but also “in use” for high-risk analytics | Azure Confidential Computing (confidential VMs and “encryption in use” patterns) | About Azure confidential VMs |
A critical SFI takeaway is that secure-by-default must be treated as a procurement requirement. If security is optional or requires bespoke customization, it will drift under operational pressure (especially during rapid AI adoption). Microsoft’s SFI narrative explicitly frames secure defaults and enforced standards as core to its approach.
Security in the AI Era: Why this Moment is Different
AI changes the threat model in four board-relevant ways.
First, training data poisoning and model manipulation turn “data quality” into a security control. OWASP’s LLM risk taxonomy explicitly flags training data poisoning and supply chain vulnerabilities as top risks for LLM applications. Recent academic work continues to treat poisoning as a training-time attack that can degrade performance or implant targeted backdoors, requiring dedicated detection and risk-driven defenses.
Second, AI expands the supply chain. The system now depends on datasets, labeling pipelines, model checkpoints, orchestration tools, and plugins. This aligns with secure software supply chain guidance emphasizing end-to-end integrity and CI/CD pipeline security controls. In practice, boards should require “model supply chain” equivalents of SBOM thinking: provenance records, signed artifacts, and controlled promotion from dev to production.
Third, AI concentrates compute and amplifies systemic risk. OECD analysis of AI infrastructure highlights concentrated segments of the supply chain (advanced chip fabrication, GPUs, and cloud provision dominated by a small set of hyperscalers). BIS analysis similarly warns that concentration in the AI supply chain can affect the operational resilience and cybersecurity of critical infrastructure.
Fourth, AI changes continuity math: model denial of service becomes a cost-and-availability risk, and “agentic” automation can turn prompt injection or tool misuse into real-world impact.
Mitigation strategies that boards can operationalize:
- Adopt lifecycle AI risk governance aligned to recognized frameworks (NIST AI RMF) so that risk ownership, measurement, and escalation are defined before deployment.
- Threat model AI systems explicitly using adversarial knowledge bases such as MITRE ATLAS to ensure security teams cover training, inference, and operational abuse patterns.
- Harden the engineering and model pipeline using SSDF guidance and CI/CD supply chain security integration strategies: secure source, secure build, controlled dependencies, and verifiable releases.
- Use isolation and confidentiality controls (including confidential computing where appropriate) for high-sensitivity analytics, particularly where multi-party or multi-tenant risks are high.
- Plan for concentration and exit as resilience requirements, not optional architecture “nice-to-haves,” aligning with the way regulators increasingly treat cloud as a critical third-party dependency in other jurisdictions.
Navigating Digital Sovereignty at the Frontier of Transformation
Digital sovereignty is often misframed as “data must stay local.” In practice, it is a set of controls that preserve
(a) where data resides,
(b) who can access it,
(c) how cross-border flows are governed, and
(d) how an organization can continue operating and exit if legal, geopolitical, or vendor risks change.
Two constraints are salient for Nigeria-based transformations today:
- Cloud geography reality. Microsoft’s public Azure regions list (as of March 2, 2026) shows African regions in South Africa and does not list a Nigeria region, which pushes many “residency” strategies toward carefully controlled cross-border architectures.
- Regulatory expectation. The Nigeria Data Protection Act applies broadly to processing tied to Nigeria (including non-resident controllers targeting Nigerians), and it anchors an accountability model for lawful, secure, and fair processing.
A practical sovereignty pattern is hybrid-by-design: keep the highest-sensitivity data domains in-country (or in tightly controlled environments), and use cloud regions for elastic analytics/AI, with enforced controls on data movement, keys, and access approvals.
Below diagram illustrates hybrid sovereignty architecture. This pattern is consistent with (a) enforced region controls, (b) customer-controlled keys, (c) strict support access governance, and (d) confidential computation for sensitive processing.
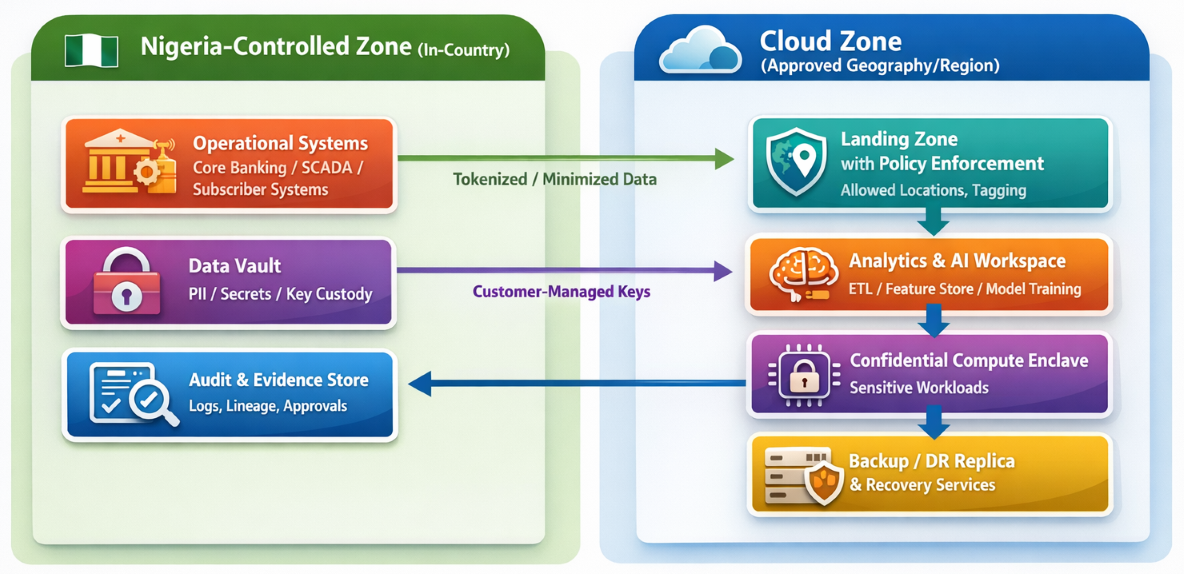
Key sovereignty controls to evidence:
- Location enforcement: Azure Policy includes built-in “Allowed Locations” controls that can deny resource deployment outside approved regions, supporting geo-compliance requirements.
- Key sovereignty: Azure documentation defines customer-managed keys and BYOK scenarios, including use of Azure Managed HSM (FIPS 140-3 Level 3) for high-assurance key custody.
- Provider support access sovereignty: Customer Lockbox for Azure requires customer approval in rare cases where Microsoft support engineers need access, and logs approvals/denials for auditability.
- Confidential processing: Azure Confidential Computing provides “encryption in use” patterns that reduce exposure in multi-tenant processing scenarios.
Securing Critical Infrastructure in Nigeria: Why Risk-based Regulation Matters
Nigeria’s regulatory direction is increasingly legible: identify critical sectors and require controls proportionate to risk, with clearer governance responsibilities, mandatory audits and reporting, and increasing emphasis on third-party risk and incident response.
The CNII Order 2024 is explicit that certain ICT systems across sectors (such as power, water, communications, finance, health, and others) are designated as Critical National Information Infrastructure, with objectives that include cohesive protection measures, continued operation, and a trusted information sharing network, alongside audits and inspections. This framing is not abstract: the schedule explicitly includes telecom towers, data center facilities, and other communications infrastructure as critical services within designated sectors.
Meanwhile, the CBN Risk-Based Cybersecurity Framework (2024) operationalizes a risk-based posture for supervised financial institutions. It clearly assigns board oversight responsibilities (including cybersecurity governance integration, budgeting, and reporting), and it formalizes domains such as third-party risk management, resilience, and emerging technologies (explicitly naming AI/ML and cloud).
The Nigeria Data Protection Act 2023 establishes an accountability and rights-based framework, with broad territorial reach (including controllers/processors outside Nigeria processing data of data subjects in Nigeria). The GAID provides more granular implementation guidance, including DPIA-style evaluation mechanics and cross-border risk considerations (for example, emphasizing risks where remedies may be harder to obtain when data is processed in other jurisdictions). (Note: widely cited analyses state GAID became effective in September 2025; the accessible directive text itself does not clearly state an effective date in the sections surfaced by automated search, so the effective-date claim should be verified against NDPC notices or official implementation communications.)
Because some sector regulator primary documents (notably the Nigerian Communications Commission website) were inaccessible for direct citation in this environment, telecom-specific reporting obligations are supported here via reputable secondary reporting that quotes or summarizes the relevant framework.
Nigeria Risk-based Regulatory Elements and Operator Implications
| Risk-based element | What regulators typically expect | Nigeria anchor instruments | Practical implications for operators |
|---|---|---|---|
| Criticality classification | Identify “critical systems,” map dependencies, prioritize recovery sequencing | CNII Order designates critical sectors and anticipates protection planning/audits | Inventory systems and data flows; define RTO/RPO tiers and dependency maps |
| Board accountability | Board-level oversight, dedicated reporting cadence, defined risk appetite | CBN framework assigns board responsibilities and reporting expectations | Establish board cyber reporting pack (KRIs, incidents, remediation progress, third-party risk) |
| Third-party and cloud risk | Contractual controls, audit rights, exit planning, and oversight of outsourced services | CBN framework includes third-party risk management and “Cloud Computing” in scope | Tighten vendor due diligence, define exit plans, test portability and recovery |
| Incident response and reporting | Faster notification, structured templates, continuous updates during containment | CBN framework includes response/remediation and restore operations domains; telecom reporting obligations widely reported for NCC CRF-NCS | Build incident playbooks with regulator notification steps; ensure SOC monitoring and reporting readiness |
| Cross-border processing risk | Evaluate jurisdictional risks, ensure meaningful remedies, document safeguards | NDPA territorial reach and rights framework; GAID cross-border risk evaluation and DPIA-style guidance | Implement data minimization, encryption, key control, and contractual safeguards for cross-border workloads |
| Information sharing and resilience ecosystem | Structured, trusted information-sharing and sector coordination | CNII Order creates a Trusted Information Sharing Network concept | Participate in sector threat-sharing; rehearse cross-operator incident coordination |
| Enforcement and auditability | Demonstrable evidence—not “policy on paper” | CNII Order provides for audit/inspection; CBN framework includes compliance/enforcement sections | Maintain evidence repositories: access logs, key logs, DR tests, vulnerability management, and audit trails |
Timeline of Key Nigeria Digital Trust Milestones
The following timeline reflects major milestones relevant to critical infrastructure security, data protection, and continuity expectations: Cybercrimes law foundations, the 2021 national cybersecurity strategy refresh, the NDPA, the CNII order, the CBN’s updated risk-based framework, and the GAID implementation directive.
Trusted Products and Services: Criteria, Examples, and Procurement Guidance
“Trusted” should be treated as an auditable, multi-dimensional property: security engineering, compliance evidence, sovereignty controls, resilience outcomes, and sustainability transparency.
Trusted Product Criteria and Procurement Questions
| Trust criterion | Board-level question | Evidence to request | Microsoft examples that map well |
|---|---|---|---|
| Secure-by-design engineering | Does the vendor prove security is built-in, not bolted-on? | Secure engineering narrative + measurable program; alignment to recognized frameworks | SFI principles and progress reporting |
| Independent compliance evidence | Can we independently evidence controls to regulators/auditors? | SOC/ISO reports; control mappings; NDA-based access to audit materials | Service Trust Portal purpose and access model ; compliance portfolio claims |
| Residency and location control | Can we enforce where resources are deployed? | Policy-as-code enforcing allowed regions; exception workflow | Azure Policy “Allowed Locations” deny control; Azure geographies support residency needs |
| Key and cryptographic control | Who controls the keys, and can we enforce separation of duties? | CMK/BYOK documentation; HSM assurance level; key access logs | CMKs and BYOK overview; Managed HSM FIPS 140-3 Level 3 |
| Provider access governance | Can the provider access our data without approval? | Explicit approval workflows and immutable logs | Customer Lockbox workflow and auditing logs |
| Confidential processing | Can sensitive analytics run with reduced exposure in multi-tenant conditions? | Confidential compute design docs; attestation patterns | Azure Confidential Computing capabilities |
| Operational resilience | Can we recover within defined RTO/RPO and prove it? | DR strategy, drills, backup policies, multi-region design, evidence | Site Recovery ensures business continuity via replication/failover; Azure Backup; availability zones concept |
| Sustainability transparency | Can we measure and manage emissions impacts of our cloud workloads? | Emissions reporting methodology and dashboards | Emissions Impact Dashboard overview; Microsoft sustainability commitments |
| Concentration and exit readiness | What is our plan if a hyperscaler region/service is disrupted or becomes non-viable? | Exit strategy, portability plan, dependency mapping, periodic tests | Industry evidence of concentration risks in AI/cloud supply chains |
Procurement Guidance for Boards and Senior Data Leaders
A rigorously “trusted” procurement decision should follow five steps.
Define the risk appetite and impact tiers for data and AI use cases (customer PII, payment rails, SCADA telemetry, subscriber metadata, model weights), and bind those tiers to explicit RTO/RPO and control requirements. This aligns with both resilience engineering guidance (designing DR around business impact) and Nigeria’s move toward risk-based sector expectations.
Require evidence-backed controls, not brochures: audit artifacts via the Service Trust Portal, enforceable geo-controls via Azure Policy, cryptographic control via CMKs/Managed HSM, and explicit support-access governance via Customer Lockbox.
Treat AI security as a lifecycle discipline: use NIST AI RMF for governance and risk measurement; use OWASP and MITRE ATLAS to drive AI-specific threat modeling; and require supply-chain controls aligned to SSDF and CI/CD supply chain guidance for both code and model pipelines.
Document sovereignty controls as a layered system: contractual controls (data processing terms, audit rights, breach notification, subprocessor transparency) combined with technical controls (location enforcement, encryption/key custody, support access approvals, and hybrid segmentation). This approach matches how modern sovereignty solutions are framed—blending policy, architecture, and operational controls.
Finally, explicitly govern concentration risk. Where national infrastructure relies on a small set of cloud and compute supply chains, resilience is not only about redundancy inside one provider; it is also about understanding shared dependencies (chips, regions, identity planes, key custody services) and pre-planning credible exit and continuity strategies.
]]>